
AI 搜索的答案到底从哪来?深度拆解大模型背后的“信息供应链”

核心导读: 当一位海外采购工程师在 AI 搜索框中输入“适用于高盐雾环境的五轴联动数控机床选型指南”时,AI 能够在短短几秒钟内,不仅给出防腐蚀材料的对比,还能精准列出几家符合标准的代工厂,并附带了技术白皮书的引用链接。这种看似“全知全能”的表象背后,并非魔法,而是一套极其精密且残酷的“信息供应链”。本文将为您深度剥开 AI 搜索的黑匣子,揭秘它的数据到底从何而来,以及 B2B 制造企业如何在这场流量洗牌中成为 AI 的“首选信息源”。
第一层:训练数据—— AI 的“九年义务教育”
AI 搜索引擎在真正联网回答你的问题之前,它的底层大模型(如 GPT 或 Gemini)已经通过阅读海量的历史互联网快照、百科全书和数字化书籍,完成了基础的“常识构建”。这部分数据构成了 AI 对工业世界的基本认知,但由于存在“知识截止日期”,它无法应对最新的非标定制需求。
- 全网网页快照(Common Crawl): 这是 AI 最庞大的底层数据源。它是一个开源项目,像一个不知疲倦的数字拾荒者,抓取了过去十几年间互联网上的数百亿个网页。当 AI 知道“伺服电机”通常与“减速机”配合使用时,就是因为它在数千万个早期的工业设备网页中反复看到了这两个词的共现。
- 结构化百科与专业文献: 维基百科、学术期刊数据库以及海量的数字化工程书籍,是 AI 建立严谨逻辑的基石。这些经过人类专家审核的高质量文本,让 AI 能够准确理解“洛氏硬度(HRC)”的定义,或者“压铸工艺”的物理原理。
预训练数据的致命局限: 这种“出厂记忆”是静态的。如果你的企业在去年刚推出了一款革命性的“超声波金属焊接设备”,由于这部分信息还没有被打包进下一代大模型的训练集里,断网状态下的 AI 根本不知道这款产品的存在。此外,如果底层数据中充斥着过时的公差标准,AI 就会产生严重的“技术幻觉”。
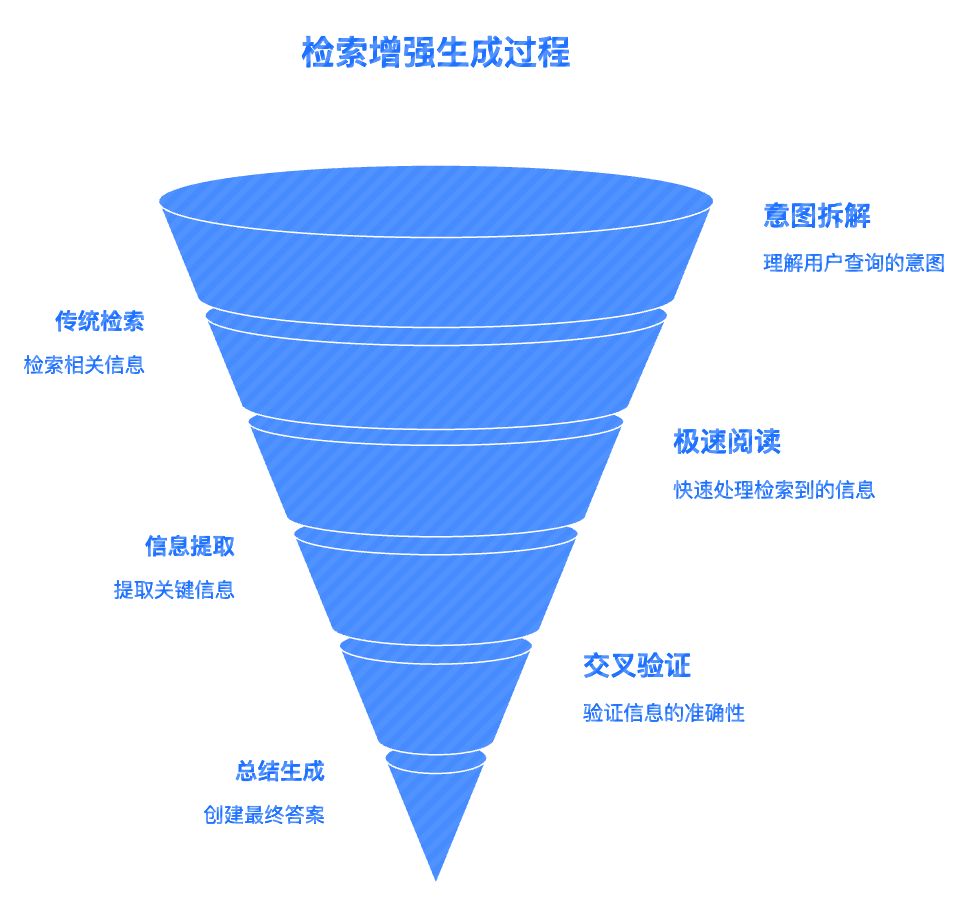
第二层:检索增强生成机制—— AI 的“现学现卖”
为了弥补底层记忆的过时与幻觉,现代 AI 搜索引擎(如 Perplexity 或谷歌的 AI 概览)采用了一套名为“检索增强生成(RAG)”的机制。简单来说,AI 在回答复杂的 B2B 采购问题时,会先化身为一个超级阅读者,去传统搜索引擎里把排名前十的网页全部读一遍,然后提炼出最终答案。
- 第一步:意图拆解与传统检索。 当客户提问“2026 年最新款高精度滚珠丝杠的承载力对比”时,AI 引擎会在后台悄悄调用传统搜索引擎(如谷歌或必应)的接口,搜索相关的长尾词,并获取排在自然搜索结果第一页的 10 到 20 个网页链接。
- 第二步:极速阅读与信息提取。 大模型会瞬间“点开”这十几个网页,如同一个经验丰富的采购总监,快速扫视网页里的产品参数表、技术白皮书和客户评价,剔除掉那些毫无营养的营销废话,只提取核心的工程数据。
- 第三步:交叉验证与总结生成。 AI 会对比这几个网页中的数据。如果 A 厂家的官网写着精度是 0.01 毫米,B 厂家的官网也写着 0.01 毫米,AI 就会确信这是一个行业标准,并将其写进最终的总结报告中,同时在句子末尾附上这两个官网的链接作为“引用来源”。
残酷的商业真相: 传统搜索引擎的排名依然是 AI 时代的生死线。如果你的 B2B 官网在传统谷歌搜索中排在第 50 名,AI 在“现学现卖”时根本就不会翻到你的网页,你的技术参数写得再好,也永远无法进入 AI 的总结报告中。
第三层:数据授权协议—— 巨头们的“金钱游戏”
随着互联网上公开的高质量工业网页即将被 AI 爬虫“吃光”,AI 巨头们开始斥资数亿美元,与全球顶级的专业论坛、新闻媒体和技术问答社区签订排他性的“数据授权协议”。未来的 AI 搜索结果,将越来越依赖这些花钱买来的“独家私域情报”。
- 公开数据的枯竭危机: 过去两年,越来越多的高质量 B2B 行业网站和技术智库,为了防止自己的心血被 AI 免费白嫖,开始在后台设置代码(Robots.txt)来屏蔽 AI 爬虫。这导致 AI 搜索引擎能抓取到的免费高质量工程语料越来越少。
- 巨头的数据大采购: 为了保持搜索结果的权威性,谷歌和 OpenAI 等巨头开始疯狂撒钱。例如,他们与全球最大的程序员社区 Stack Overflow、以及拥有众多细分专业板块的 Reddit 论坛签订了天价合同,获得了实时读取这些论坛内部讨论数据的特权。
对 B2B 制造企业的深远影响: 当海外采购商向 AI 询问“某某品牌的注塑机售后服务到底怎么样”时,AI 不会只看你官网上的自夸,它会直接去调取它花钱买来的 Reddit 工业板块或专业问答社区里的真实用户吐槽。这意味着,B2B 企业的品牌阵地必须从单一的官网,向这些被 AI 巨头“官方认证”的第三方权威社区转移。
B2B 制造企业如何成为 AI 搜索的“首选信息源”?
在彻底弄懂了 AI 搜索的“信息供应链”后,B2B 制造企业必须立刻抛弃过去那种“堆砌关键词骗点击”的旧思维。你要做的是主动向 AI “喂料”,把你的官网改造成一个结构清晰、信息密度极高的“机器可读智库”。
- 全面部署结构化数据(Schema): AI 爬虫没有耐心去阅读你网页上花哨的排版。你必须在网站后台使用国际通用的代码格式,明确标注出哪一段是“产品型号”、哪一段是“加工精度”、哪一段是“常见技术问答”。这种结构化标签就像是给 AI 递上了一张清晰的名片,让它在抓取信息时毫不费力,从而大幅提高你的网页被引用的概率。
- 提供极高的“信息熵”(干货密度): AI 极其厌恶“领先的解决方案”、“卓越的品质”这种空洞的营销词汇。当撰写技术文章或产品详情页时,请大量使用具体的测试数据、CAD 图纸截图、故障排查步骤以及清晰的对比表格。你的内容越硬核、越像一份严谨的工程报告,AI 就越倾向于把你作为权威信源推荐给采购商。
- 抢占第三方权威平台的声量: 既然 AI 搜索在生成答案时,极其看重多方交叉验证,你就不能只在官网上自说自话。你需要主动将你们的技术白皮书发布到行业权威的工程期刊网站上;在海外专业的机械制造问答社区中,用真实的工程师身份去解答技术难题。当 AI 发现全网的专业节点都在指向你的品牌时,你就会成为该领域的“免检答案”。
结语:拥抱 AI 语义,重建 B2B 数字护城河
AI 搜索的本质,是从“提供网页链接”向“直接交付专业答案”的范式转移。在这个由大模型主导的新世界里,谁能提供最结构化、最真实、最深度的工业数据,谁就能垄断海外大客户的采购入口。
面对这场流量入口的底层洗牌,传统的建站与优化手段已经捉襟见肘。作为深耕 B2B 制造领域的数字化增长专家,易歌科技 致力于帮助中国制造企业打造符合 AI 抓取标准的下一代数字基建。
从基于大模型逻辑的生成式引擎优化(GEO),到极其严苛的网站结构化数据部署,再到高信息密度的 B2B 技术内容矩阵搭建,易歌科技为您提供全链路的出海破局方案。不再让千万级的采购订单在 AI 的“隐形候选名单”中悄然流失,联系易歌科技,让您的品牌成为 AI 时代最权威的工业智库。
常见问答
Q1:如果 AI 搜索直接在结果页把我的技术参数都总结出来了,客户不进我的网站了,我岂不是白白流失了流量?
A1: 这是一个普遍的误区。对于 B2B 制造业这种高客单价、长决策周期的行业,采购工程师绝不会仅凭 AI 的几句总结就下几百万的订单。AI 的总结只是一个“初步筛选器”。如果 AI 在总结中引用了你的网站,并标注了你的品牌,采购商为了获取更详细的图纸或报价,一定会点击那个引用链接进入你的官网。这种被 AI 筛选过的流量,其询盘转化率远高于传统的泛流量。
Q2:我可以在网站后台写代码(Robots.txt)禁止 AI 爬虫抓取我的产品数据吗?
A2:技术上完全可以,但商业上极其危险。如果你屏蔽了 AI 爬虫,你的竞争对手却没有屏蔽。当海外客户向 AI 询问相关设备时,AI 的数据库里根本没有你的存在,它会把所有的订单机会都推荐给你的同行。在 AI 时代,被屏蔽就等于被市场抹杀。
Q3:为什么我们在谷歌传统搜索排在第一页,但 AI 搜索生成的答案里却从来不引用我们?
A3:传统排名高只意味着你的“权重”高,但不代表你的“内容适合被总结”。如果你的网页全是图片、Flash 动画,或者大段的营销废话,缺乏清晰的段落标题(H2/H3)、对比表格和明确的数据结论,AI 爬虫在阅读时会觉得“提取信息的成本太高”,从而转去引用排名靠后但排版极其清晰、数据详实的竞争对手网页。
Q4:对于极其冷门的非标定制设备,AI 搜索的数据来源会不会很不准?
A4:确实会。由于冷门设备的公开网页数据极少,AI 很容易出现“幻觉”或拼凑错误信息。但这恰恰是你的巨大机会!只要你能在官网上针对这些冷门非标设备,发布极其详尽的参数说明、应用案例和常见问题解答(FAQ),由于全网没有其他竞争者,AI 搜索在遇到相关提问时,将 100% 依赖并引用你提供的唯一数据源。